

Let's take a look at how using chimp can benefit your workflow when working on GraphQL Apollo Server.
Read through or watch the video here:
With chimp
First, we will take a look at adding a new module with a query with Chimp.
We will be using https://github.com/xolvio/chimp-gql-tiny-example repo with the default branch of data-sources-with-chimp
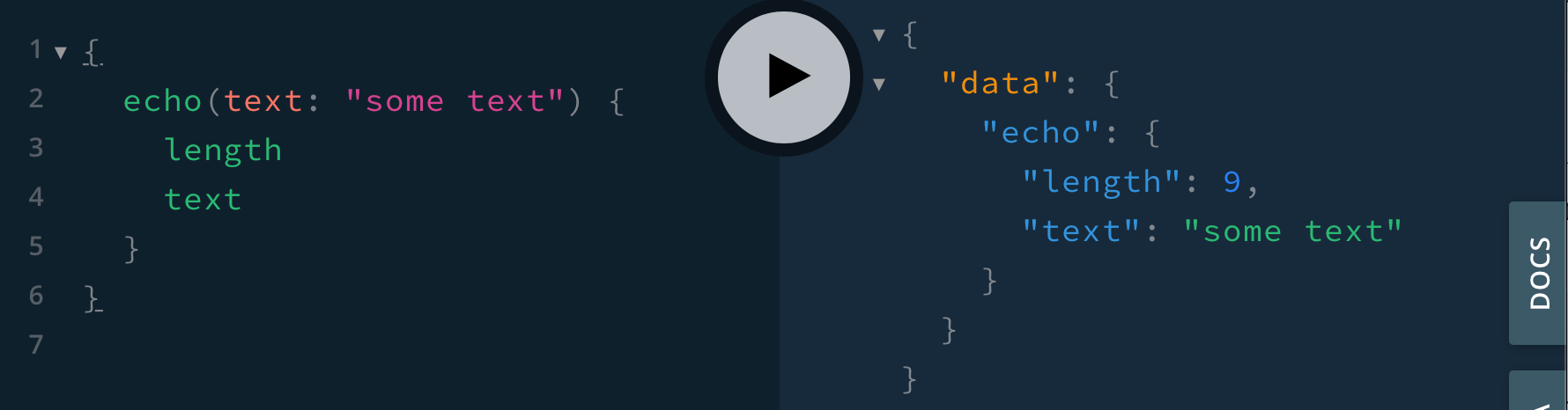
First let's create a new module with graphql file: ./src/Echo/Echo.graphql
Take note that we use the @computed directive to tell Chimp to generate a field-level resolver for that field.
Now generate all the things (using chimp):
You will see a few new files, in particular one with a resolver for the Query and one with the resolver for the EchoResponse.length field.
Let's take a look at the Query first:
And replace throwing an error with returning the object with text:
Now the field level resolver:
Let's replace the error with returning the length for the text that comes from the parent (in our case - the Echo Query)
And that's it! You can start the server (npm start) and check the query:
Without chimp
Now for the non-chimp part!
We will be using https://github.com/xolvio/chimp-gql-tiny-example repo with the data-sources branch.
Similarly to Chimp - let's create ./src/Echo/Echo.graphql
Now we have to manually create the resolvers file and implement it. I usually copy and paste a small resolvers file from a different module and modify it to the shape I need.
src/Echo/echoResolvers.ts
Now we need to manually add it to the existing resolvers:
You can start the app and run the query, it should work exactly the same way.
So, what's the big deal? Both options seemed easy.
The difference is in the fact that doing things manually is error-prone, there are literally tens of ways you could make this not work on the non-chimp part, from not adding the resolvers (or not adding them correctly), to not implementing the resolvers properly. I had a dry run for recording a video for this article, and then the final one. In both cases, I made an error in implementing the Echo Query resolver. Instead of returning {text: args.text} I just returned the args.text (as if the query should return a String, not EchoResponse - which is an object). The first time around I made that mistake in the non-chimp case and hit a runtime error when running the query. It took me a few minutes to figure out what's wrong. The second time around I made that mistake with the chimp watching my back - and the moment I made the error typescript shouted at me, that I'm returning a string instead of an object. In general - the sooner you get the feedback while coding, the less time it will take to fix a problem, and the more likely you are to stay in the flow (which is where happiness comes from ;-) )
Obviously, you could have manually generated types based on your schema, and then manually attach them to your resolvers, but it's not really straightforward, people forget to do that, or do it incorrectly. It's also easy to get the shape of the resolvers correct, so you could have the types happy, but runtime again. You could also just forget to implement a field-level resolver - with the chimp, it's generated for you with a failing test, so it's tough to miss.
And speaking of tests - we generate the scaffolds for your tests. Here we didn't implement them to make the comparison more apples to apples, but they make testing super easy, which is definitely not the case when working with a typical apollo server.
Let me know if you have any questions or thoughts in the comments below.




